Mysql CharacterSet and Collation
Character set is a set of symbols and encodings, whereas collation is a set of rules for comparing characters in a character set.
Let’s understand the concept with an example:-
Suppose we have an alphabet with 4 letters: A,B,a,b. We give each letter a number: A=0, B=1, a=2, b=3. The letter A is a symbol, 0 is the encoding for A. The combination of all 4 letters and their encodings is a character set.
Suppose we want to compare two string values A and B, the simplest way to do so is using encodings: 0 for A and 1 for B. As 0 is less than 1, we say A is less than B. Here, we’ve just applied a collation to our character set. Hence, collation is a set of rules (only one rule here, to compare the encodings).
There may be different types of collations available like:-
ci/cs: (case insensitive/ case sensitive) : it has a separate rule in case of case insensitivity, i.e. upper and lower case are the same.
ai/as: (accent sensitive/accent insensitive): many of character sets may not just have alphabets/numbers/special characters, but some also special characters such as é, í, ó, ú, ý, Á, É, Í, Ó, Ú. Collations can have different rules to whether to have distinction between them/ whether considered the same.
A character set (also called character encoding) is a way to encode characters so that they fit in memory. That is, if the charset is ISO-8859-15, the euro symbol, €, will be encoded as 0xa4, and in UTF-8, it will be 0xe282ac.
The collation is how to compare characters, in latin9, there are letters as e é è ê f, if sorted by their binary representation, it will go e f é ê è but if the collation is set to, for example, French, you'll have them in the order you thought they would be, which is all of e é è ê are equal, and then f.
To see all available charsets and collations:
Show character sets [like ‘’];
Show collations [like ‘’ / where charset like ‘’];
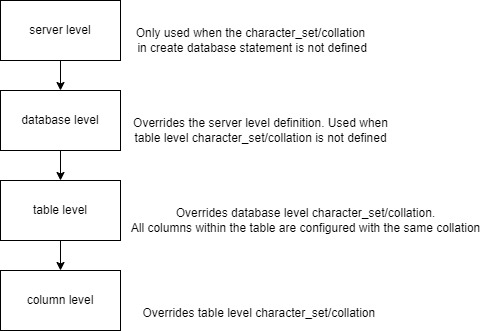
Charset and Collations Levels
Server charset and collation
Defined by: character-set-server & collation-server
The server character set and collation are used as default values if the database character set and collation are not specified in CREATE DATABASE statements. They have no other purpose.
Database Character Set and Collation
Create database and alter database statements have an optional clause for specifying database charset and collation.
CREATE DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
ALTER DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
The character set and collation for current default database is determined from the values of character_set_database and collation_database variables. Changed when the default db changes.
Also, the character set and collation of database can be seen from
SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name';
Table Character set and collation
Create table and alter table statements have optional clauses for specifying the table charset and collation.
CREATE TABLE tbl_name (column_list)
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]]
ALTER TABLE tbl_name
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]
The table character set and collation are used as default values for column definitions if the column character set and collation are not specified in individual column definitions.
Column Character Set and Collation
CREATE TABLE t1
(
col1 VARCHAR(5)
CHARACTER SET latin1
COLLATE latin1_german1_ci
);
Character String Literal Character Set and Collation
For the simple statement SELECT 'string', the string has the connection default character set and collation defined by the character_set_connection and collation_connection system variables.
Imp
What character set are statements in when they leave the client?
The server takes the character_set_client system variable to be the character set in which statements are sent by the client.
What character set should the server translate statements to after receiving them?
To determine this, the server uses the character_set_connection and collation_connection system variables:The server converts statements sent by the client from character_set_client to character_set_connection. Exception: For string literals that have an introducer such as _utf8mb4 or _latin2, the introducer determines the character set. See Section 10.3.8, “Character Set Introducers”.
collation_connection is important for comparisons of literal strings. For comparisons of strings with column values, collation_connection does not matter because columns have their own collation, which has a higher collation precedence (see Section 10.8.4, “Collation Coercibility in Expressions”).
What character set should the server translate query results to before shipping them back to the client?
The character_set_results system variable indicates the character set in which the server returns query results to the client. This includes result data such as column values, result metadata such as column names, and error messages.
Repertoire
The repertoire of a character set is the collection of characters in the set.
String expressions have a repertoire attribute which has two values:
ASCII: Can only contain ASCII characters. Ie. unicode range U+0000 to U+007F.
UNICODE: It is a superset. Contains characters in unicode range U+0000 to U+10FFFF.
Since ascii range is a subset of unicode range, a string with ascii can be converted safely without loss to a charset of unicode repertoire or any charset that is a superset of ascii charset.
Every character set is a superset of ascii with the exception of swe7.
Unicode/UTF-8-character table (utf8-chartable.de)
The use of repertoire enables character set conversion in expressions for many cases where mysql otherwise would return “illegal mix of collations”.
Let’s see an example:
select _utf8mb4’def’;
Here, although the character set is explicitly defined as utf8mb4, the actual repertoire is ascii instead of unicode since the characters are not outside ascii.
CREATE TABLE t1 (
c1 CHAR(1) CHARACTER SET latin1,
c2 CHAR(1) CHARACTER SET ascii );
INSERT INTO t1 VALUES ('a','b');
SELECT CONCAT(c1,c2) FROM t1;
Without repertoire,
ERROR 1267 (HY000): Illegal mix of collations (latin1_swedish_ci,IMPLICIT) and (ascii_general_ci,IMPLICIT) for operation 'concat'
Using repertoire, subset to superset (ascii to latin1) conversion occurs and the result is returned. ------+ | CONCAT(c1,c2) | +-------
--------+ | ab | +---------------+
Coercibility
Defines if a charset/collation can be converted to another charset/collation.
The different levels of coercibility:

How to check coercibility of something ?
SELECT COERCIBILITY(_utf8mb4'A' COLLATE utf8mb4_bin);
-> 0
SELECT COERCIBILITY(VERSION());
-> 3
SELECT COERCIBILITY('A');
-> 4
SELECT COERCIBILITY(1000);
-> 5
SELECT COERCIBILITY(NULL);
-> 6
How does conversion occur ?

Out of mind!!!!!!!!!!
There is a particular type of error that throws “An illegal mix of collations” even if there seems a way for conversion.
Create a table with latin1 columns:
> CREATE TABLE `table_latin` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`char_id` char(6) NOT NULL,
`v` varchar(128) NOT NULL,
PRIMARY KEY (`id`),
KEY `char_id` (`char_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
> insert into table_latin (char_id, v) values (‘aaaa’, ‘bbbb’);
> set names utf8mb3; (sets connection_character_set/ collation = ‘utf8mb3’)
> SELECT char_id FROM `table_latin` UNION ALL SELECT 'N/A'
This works perfectly fine. Since the table column char_id has lower coercibility (2) compared to that of the literal string ‘N/A’ (4), the utf8mb3 literal string gets converted to latin1 (since both have only ascii repertoire).
However, on executing slightly modified form of the query:
> SELECT char_id FROM `table_latin` UNION ALL SELECT * FROM (SELECT 'N/A') a
It throws the following error:
Illegal mix of collations (latin1_swedish_ci,IMPLICIT) and (utf8mb3_general_ci,COERCIBLE) for operation 'UNION'
If I check the coercibility of the nested query, it is still 4.
> SELECT coercibility(a.test) FROM (SELECT 'N/A' as ‘test’) a
> 4
A similar type of bug has been reported on mysql:
MySQL Bugs: #70645: Illegal mix of collations despite of different coercibilities
Is this a bug or am I missing something ?
Mysql joins between tables with different character sets:
Create two tables:
CREATE TABLE `table_latin` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`char_id` char(6) NOT NULL,
`v` varchar(128) NOT NULL,
PRIMARY KEY (`id`),
KEY `char_id` (`char_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `table_utf8` (
`char_id` char(6) NOT NULL,
`v` varchar(128) NOT NULL,
PRIMARY KEY (`char_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into table_latin (char_id, v) values (‘aaaa’, ‘bbbb’);
insert into table_utf8 (char_id, v) values (‘aaaa’,’sfdsdfasfd’);
explain select * from table_latin t1 join table_utf8 t2 on t1.char_id = t2.char_id;
This works but the reference index used for join is not used due to which the query gets too slow. If we see the warnings:
show warnings;
Cannot use ref access on index 'char_id' due to type or collation conversion on field 'char_id'
However, we cannot join two tables with same character set, but different collation. (collation defines comparison rules, while join with ‘=’ operator which is type of comparison if we think. So comparing two rows having different comparison rules doesn’t make sense).


This is wonderfully put together! I appreciate how every element seems intentional, contributing to the overall impact. The design, presentation, and thought process behind it are clear and admirable. You should be proud of the result—it’s professional, creative, and inspiring to see work done at this level. Data Engineering
ReplyDelete